Command Line Interface Intro: Part 10
by Peter Kelly (critter)
With the release of the Unix operating system in the early 1970's, there was finally a solid operating system and a set of tools that had been written to utilize the advanced features that it supported. The computing community welcomed it, and some of the tools raised a lot of interest. One of these was the C programming language developed by Dennis Ritchie to enable the system and the tools to be so rapidly developed. Another one was sed, the stream editor. Because of the interest generated by sed and some of the other text manipulation tools, three of the engineers at Bell Laboratories set about developing a programming language that would refine and simplify some of the work done with these tools. It was released in 1977 under the name awk, which was derived from the initials of the three developers Alfred Aho, Peter Weinberg and Brian Kernighan. Brian had worked with Dennis Ritchie on the C Language, (The basic C language is still known as K & R C), and a lot of the structure of C found its way into awk.
Awk was written to enable quick and dirty commands to be constructed to strip and reformat lines of text, but by the mid 1980's so much was being done with this program, much to the surprise of the authors, that it was re-visited to become nawk (new awk). Much more programming functionality was added to help it become the scripting utility that we have today. Linux users will most likely have gawk, which is similar enough to nawk as to make no difference to most users.
You may see awk written as 'awk' and as 'AWK'. It is generally agreed that awk is the interpreter program for awk scripts, and AWK is the scripting language used in those scripts.
AWK
Alfred Aho, one of the developers, described awk like this:
"AWK is a language for processing files of text. A file is treated as a sequence of records, and by default each line is a record. Each line is broken up into a sequence of fields, so we can think of the first word in a line as the first field, the second word as the second field, and so on. An AWK program is a sequence of pattern-action statements. AWK reads the input a line at a time. A line is scanned for each pattern in the program, and for each pattern that matches, the associated action is executed."
This pretty much sums up what it does, but doesn't even begin to do justice to the power and flexibility of the language — as we shall see.
Using awk need not be a complicated affair. It can be a simple one line command issued at the console. awk '{ print $1 }' test would print out the first word or 'field' on each line of the file test. The variables $1, $2 ... etc. are assigned to the corresponding fields in a record. The variable $0 contains the entire input line/record, NF the number of fields in the current record and NR the number of the current record.
We should pause here and be clear about with what it is that we are working.
A 'word', which is also referred to as a 'field', is not only a language word it is a contiguous group of characters terminated by white space or a newline. White space is one or more spaces or tabs, and is the default field separator. This can be changed to any arbitrary character by use of the -F option (uppercase) on the command line, or by setting the variable FS in a script. awk -F":" '{print $1}' /etc/passwd changes the field separator to a colon and prints out the first field of each line in the file /etc/passwd which provides us with a list of all named users on the system.
A record is a group of fields and can be considered as a card in a card index system. The data on the card can be details from a directory listing, a set of values from the result of some test or, as we have seen, a line from the system /etc/passwd file. The variable RS contains the record separator, which by default is set to a newline \n. Changing the value of RS enables us to work with multi-line records.
The command line syntax of the awk command is as follows:
awk {options}{pattern}{commands}
The options for awk are:
-F to change the field separator -f to declare the name of a script to use -v to set a variable value.
We could have used -v FS=":" to change the field separator.
There are some others, but as most awk usage is done in a script, they are little used.
pattern is a regular expression set between a pair of forward slashes as in sed and is optional. If omitted, the commands are applied to the entire line.
commands are also optional, and if omitted, any line that matches pattern will be printed out in its entirety, unchanged.
If both pattern and command are omitted then you will get a usage reminder, which is no more than you deserve.
If using awk in a shell script, then its use is more or less as on the command line.
An awk script is called in one of two ways:
1. Create a script file named awkscript or whatever:
{
FS=":"
print $1" uid="$3
}
Call it with the -f option: awk -f awkscript /etc/passwd
2. Add a line like this as the first line of the script:
#!/bin/awk -f
I prefer to give files like this an 'awkish' name — uid.awk.
Make it executable: chmod +x uid.awk. Call it like this: ./uid.awk /etc/passwd. The #! line must contain the actual address of the awk executable, which you can check with the command which awk.
Actually, if you are running Linux, awk is more than likely a symbolic link to gawk, the gnu version of awk which has a few extras, but everything here will work with either version — unless otherwise stated. If you want to know which one you are actually using, the command awk --version will tell you.
In the script we just created, everything between the braces is executed once for each line of the input file or each record. We can also have a 'header' and a 'footer.' These are known as the BEGIN and END blocks. This is where we put code that we want to execute just once at the beginning or at the end of execution. The BEGIN block is where we would normally initialize variables such as FS, and the END block can be used to print a final completion message or summary of completed commands.
The script then consists of three sections:
BEGIN{
commands}
{ command
|
This is the main part of the script
|
command}
END{
commands}
All of the sections are optional, although omitting all three would prove pretty pointless. The following code prints out the name of all users on the system who have bash as their default shell.

Note that the slashes need to be escaped. Here, I have used two equal signs as the equality symbol, but awk also uses the tilde ~ symbol to match regular expressions. Normally, we use this as shorthand for our home directory.
But what does it do?
Well it processes text and other data.
Yes, sed does that, but if you liken sed to the search and replace functions in a word processor, then with awk you can add to that the programming power of a high level language like C, floating point calculations including trigonometry and exponentiation, string manipulation functions, user defined functions, data retrieval, boolean operators and multi-dimensional and associative arrays. Unix/Linux commands often generate tabulated test output, and awk is the ideal tool to generate reports from this type of data, easily providing a header, selecting and manipulating selected parts of the data and then providing a final section to calculate and output a summary.
In short then, awk is a report generator and advanced scripting language that will do almost anything, although without some serious hardware modifications, it will not make your coffee.
With such a complex program as awk, it would be reasonable to assume that learning to use it was going to be an uphill struggle, but fortunately this is not the case. If you have followed along so far through shell scripting, regular expressions and sed, then you have already covered most of the hard work. There are some differences, but nothing that will hurt your brain.
Simple awk scripts
Although awk can be, and often is, used on the command line, it becomes most useful when used in a script. The script can be saved and easily modified to perform other similar tasks.
Suppose we wanted to know which ext file systems were listed in /etc/fstab, and where they would be mounted. We can do this easily with awk using an if conditional statement. I have used a nested statement here to ensure that comments are excluded.
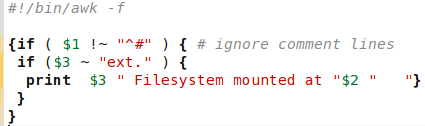
This reads 'If the first field does not begin with a #, then if the third field contains "ext" followed by one other character, then print out the file system type and its mount point.'
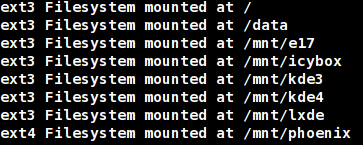
This is the output on my machine from the command ./awk1.awk /etc/fstab.
awk is often thought of as an alternative to sed, and it can indeed be used as such. Which one you use depends upon what you need to do. Remember the tortuous route we had to go in sed to output the size, re-formatted date and file name from a directory listing?
sed -n -e 's/M/ MegaBytes/' -e 's/-.\{12\}\(.\..
MegaBytes\) \([0-9]\{4\}\)-\([0-9][0-9]\)-\([0-9][0-9]\)
..:.. \(.*$\)/\4\/\3\/\2 \1 \5/p' sed-demo
To do this in an awk script we can start by only considering records (lines) that: start with a hyphen (line 3), and that contain 6 fields (line 4).

In line 5, we call the built in function sub(), which substitutes "MegaBytes" for the "M" in the third field.
In line 6, we call another built in function called split(). This splits up the fourth field, the date field, using a hyphen as the field separator, and stores each part as an element of an array named fdate.
Line 7 restricts operation to only those lines where the third field ends in "BYTES."
Line 8 prints out the re-formatted date, pulling the elements from the array, followed by the size and file name fields.
Even though the script contains a lot of material that you have never seen, I believe it is a lot less daunting than its sed counterpart, and the output is identical.
Of course awk can also be called from a shell script, and indeed many system scripts make extensive use of awk. There is an important concept to consider when calling awk from whithin a shell script. In a shell script, the $ indicates a variable name such as $USER, whereas in awk, it references a field, such as $2, which refers to the second field in a record.
When you call awk in a shell, the awk commands must be single quoted to protect them from shell expansion. If you passed awk the command '{ print $USER }' expecting the output to be the users name as the shells echo command would output, you would be in for a surprise.
Awk does not see the variable, but sees a reference to field number 'USER'. As USER is not defined, it has a zero value, hence $0, and the entire record is output.
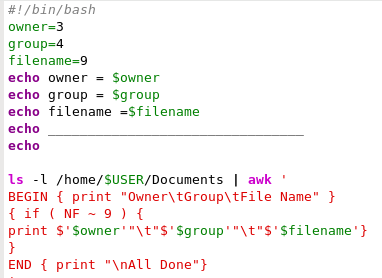
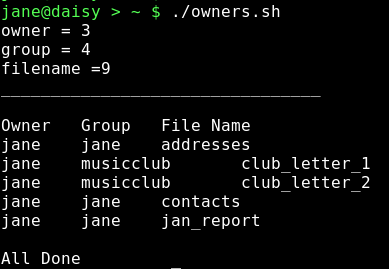
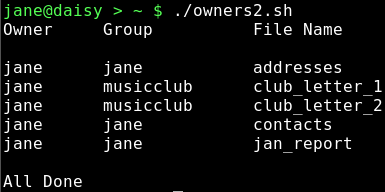
In this bash script, we pipe the output from a directory listing of the users home directory into an awk command, which outputs the owner, group and file name of each entry.
The first part of the script assigns the values to the variables, and then echoes them to screen to show the values that they have in that part of the script. The directory listing is then piped into the awk command, which has a BEGIN section to print a header, the main section has a single print statement which is applied to all input lines with 8 fields and an END section to end the report.
Syntax highlighting shows how the quoting is turned on and off to allow or deny shell expansion.
Each unquoted variable is expanded to its value so that print $'$owner' becomes print $3 (the third field). Two $ signs are required, as $owner is seen as simply 3. The \t in the command is a tab character.
The use of built in functions, as used in the script, demonstrate some of the power available in awk. So perhaps we should look at some of the available functions, what they do and how we call them. awk's built in functions can be grouped as:
- text manipulation functions
- numeric functions
- file handling functions
File handling functions in awk are best left alone. Use something more suitable wherever possible. If you need to control the opening and closing of files, call the awk command from within a shell script and let the shell control the files. Shells excel at file handling.
Integer numeric functions included in awk are quite complete, and should satisfy the needs of most people. Floating point operations in awk are fine if you need them, or as a work around to the shell's inability to handle floats, but remember to return the value to the shell as a text string. I have found little use for these functions in awk, despite my daily work requiring a considerable amount of mathematics, there are always better tools for this, just as you wouldn't write a letter in a spreadsheet even though it is possible.
Text manipulation functions are really what awk is all about, so I'll start with those.
Substitution is a common task, and awk provides three functions to achieve this:
sub() and gsub(). These are analogous to the s command in sed and the s command with g(lobal) option.
gensub() This a general substitution function in gawk. It is not found in the original awk, so beware if your code is meant to be portable.
The first two functions are called by sub(/regexp/, replacement, search-target). This is like saying "substitute( whatever-matches-this, with-this, in-this)."
The 'in-this' part is where to search for the match, and can be a variable ($myvar), a reference to a field ($1) or an element of an array (array[1]). If omitted, then $0 (the entire record) is searched. Note that if the search-field is omitted, then omit the second comma or you will get an error.
This enables you to easily replace a particular occurrence where multiple matches may be possible within a record.
The gsub() function works identically with the search target, restricting the 'global' replacement to a particular part of the record. The gensub() function is called by gensub(/regexp/, replacement, how, search-target).
The parameter how is new. If it is g or G, then all matches are replaced. If it is a number, then only the match corresponding to that number is replaced. sub() and gsub() modify the original string as it passes through, as demonstrated in our first little script where 'M' was changed to ' MegaBytes'. (The string or record is modified, not the original file). gensub() does not alter the original string, but returns it as the result of the function. Therefore, an assignment is required to make use of the changes.

This changes the first occurrence of the string "jane" to "me," and returns the result in the variable "owner." As the first occurrence of "jane" is in the third field of the file listing, we can see that "owner is indeed "me," but the original third field $3 is unchanged, as we can see by printing out $0 — the original input record.

Instead of assigning the result of the function to a variable, it can be assigned directly to the print command like this:
print gensub(/jane/, "me", "1" )
split() is another function used in the first example and is an extremely convenient tool to have around.
Split( string_to_split, name_of_an_array, separator )
It takes a string, specified as the first parameter, searches for what is specified as a separator in the third parameter, and stores each separated 'chunk' as an element of the array specified as the second parameter. The separator can be a single character or a regular expression. If it is omitted from the command, then the current value of the awk variable FS is used. If it is the empty string "", then each individual character is stored in a separate element of the array. The return value of the function is the number of elements in the array.
This is great for tasks like dealing with names and addresses, or for converting a numerical value into its text equivalent.
In this example we feed a date to the script in a space separated numeric form and output the date with a textual month.
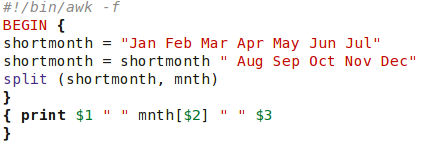
The months are pre-loaded into an array in the BEGIN section of the script. The second assignment statement needs to include a separating space at the beginning, or we would get a month called 'JulAug'. Also, in the second assignment statement is another feature of awk, concatenation by including a space between the variable name and the string to be joined to it.

length() a nice, easy one. length( string)
It simply returns the length of the supplied string or, if no string is specified, the length of the current line $0.
substr() substr( string, start-position, max_length )
This function returns the sub-string that begins at start_position, and extends for max_length characters or to the end of the string. If max_length is omitted, the default is the end of the string. The function returns the sub-string found. It is not used to change a part of a string. Use sub() for that. These functions can also be used on the command line, although they a more usually found in scripts.
To demonstrate command line usage, we can send the output from the uname -r command (which shows the release of the currently used kernel) through a pipe to awk, and apply the substr() function to find only a part of the output and print that part to screen.

When you need to find the position of a sub-string within a string awk provides the index() function.
index( string, substring )
The return value is the start position of the sub-string, or 0 if it is not found.


We find the start of the processor description, and then use the return value to cut out a sub-string from there to the end of the line. In this way, we don't have to know how many words will be in the description.
A similar function is match().
match( string, regular_expression )
Instead of searching for a simple substring, the match() function uses the much more powerful regular expression pattern matching. The return value is, like index(), the starting position of the match, but this function also sets the value of two of awks variables: RSTART & RLENGTH
Here's a file we created right at the beginning of this course:

If we look for the beginning of the time string in the second line:

We get this result, only the second line contained a match.

Something that we often need to do is to convert the case of characters or strings from upper case to lower case, or from lower to upper.
Awk has a pair of functions that automate this process. They are called, not surprisingly toupper() and tolower(). They each take a single string as an argument and return a copy of that string, with all of its characters converted to the respective case.
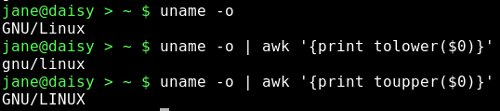
What could be easier?
While we are dealing with text, I should mention the sprintf() function.
This function works just like the printf() function we used in bash shell scripting, except that this one doesn't print out the text. It returns a formatted copy of the text. This is extremely useful and can be used to create nicely formatted text files, where the fields of a record may be of indeterminate size.
You probably noticed that the output from the owners.sh script we used to demonstrate passing variables in a shell script was ragged and untidy. If we use the printf statement, instead of the simpler print command, we can specify exactly how we want the report to look.
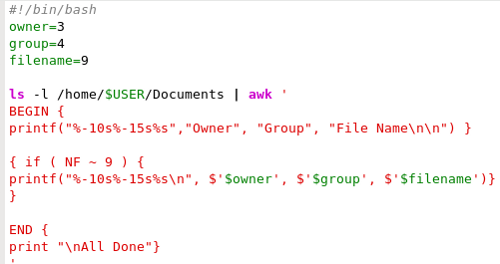
The formatting rules are the same, and the fields to be output can be given a fixed width or, in the case of numerical fields, a pre-determined format or number of decimal places. Leading and trailing zero suppression is supported, as is padding of shorter fields with spaces or zeroes, as appropriate. Actually, all variables in awk are stored as strings, but variables containing numeric values can be used in arithmetic functions and calculations.
A nice feature of awk is that arrays are associative. What this means is that an array is a group of pairs. An index and a value. The index doesn't have to be an integer, as in most programming languages. It can be a string. The index is associated with the value. The order then is irrelevant, although you can use numbers as the index to an element of an array.
Its numerical value has no meaning in awk, only the fact that it is associated with a particular value is of interest. This makes arrays in awk particularly flexible and efficient. In most programming languages, arrays must be declared as to the type of values that will be stored, and the maximum number of elements that will be used. A block of memory is then allocated for that array, and size and type cannot be changed. awk, however, doesn't care about any of that. The indices may be anything that you wish. The stored values may be any mix of things that you wish, and you may add as many elements as you wish.
Associative arrays are particularly useful in look up tables. If you had a text file named phonetic with contents like this:
a Alpha b Bravo c Charlie : : y Yankee z Zulu
Then we could read it into an associative array and use the array to convert characters to their phonetic equivalents.


If you happen to run out of steam with awks built in functions, or you find yourself repeating code, there is nothing to stop you writing your own functions. Functions must be declared before any code that uses them, pretty obvious really except that they must be declared before the code block that calls them. This means that the function code should usually be written outside of and before the main loop.
The syntax for a function declaration is function function_name ( parameters ) {actions}. The keyword function is mandatory.
function_name may be almost anything you like that is not a reserved word, a variable name or a pattern of characters that could be wrongly interpreted by awk. It should also begin with a letter or underscore character.
parameters are a comma separated list of variables that get passed to the function by the calling code.
The names of the parameters are used by the function, and do not have be the same as the name of the argument being passed. Only the value is passed to the function. Mostly though, it is less confusing if the names are kept the same.
Any actions inside the braces are what the function does with the passed parameters, and if a return statement is included, then that value will be returned to the calling code.
If a script called a function name myfunction with the command result = myfunction( string), then return newstring in the function code would return the value that the variable newstring holds in the function to the variable result.
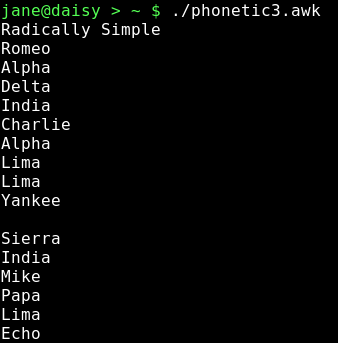
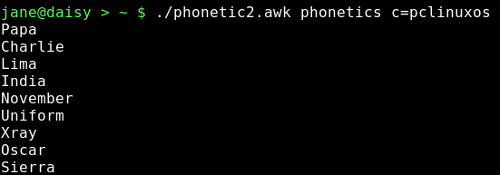
If we wanted to make more use of our phonetics script by passing it any phonetics look up list and an arbitrary string to translate, we could write a function to do the translation.

The function appears before the main loop and has two parameters passed to it, c is the string to translate and codes is the array of lowercase letters and their associated phonetic codes. The string is split into single characters by using an empty string as the field separator, and then stored in an array named letters. The length of the string is required to limit the loop, which loops round from one to the number of characters in the string printing the code that corresponds to the current letter.
In the main loop, the input data file named phonetics is read into the codes array. In the END section the function is called and passed the string c, which is passed on the command line, and the codes array.
Here is the output from a sample run.
Passing the name of the data file on the command line is useful if there are several data sets that you wish to switch between, but if there is only one, we can get the script to read it in by using awks getline function.

In the BEGIN section, the data file is read in using a while loop to repeat the process until we get an empty line. Each line is stuffed into the array codes. The string to translate is converted to lowercase at the start of the main loop, and in the body of the function, a check is made with a regular expression to see if the letter is in the range a-z, in which case it gets converted. If it is not in that range, then it is output as is, this takes care of spaces, numbers and punctuation. The strings to be converted may be piped in to the script, or can be typed interactively on the command line as below.